AWS Appsync and GraphQL
This post is part of a series on the learnings and observations gathered along the GraphQL journey at Houghton Mifflin Harcourt!
Why GraphQL?
With Microservice architectures and best practices adopted by most modern software development groups, it is quite common for application developers to integrate with a handful of microservices for delivering a feature and would often raise questions such as:
- Are the domain objects well documented and normalized?
- How many services do we need to integrate with and how does that add to the code complexity?
- How does the service integration change the performance characteristics and data transfer overhead?
- API security? State management? Caching? and many more…
GraphQL certainly eases a lot of these pain points, simplifies code development, eases maintenance over time, minimizes data transfer, and most importantly allows us to develop smarter, ship faster, and scale better!
Evolution of GraphQL @HMH
At Houghton Mifflin Harcourt we work hard to improve and optimize our user experience. With microservices and REST APIs, we entered a problem space for the front-end applications. The need for integrating with a bunch of microservices and the lack of a normalized data model introduced code complexity as well as latency. Options such as optimized web path, background loading, async implementations, and a few others were looked at but still didn’t provide a great experience from a performance standpoint with the number of roundtrips an application had to make. GraphQL does orchestration very well and can work in tandem with REST. We explored an aggregation pattern where we could have a single service aggregating from more than one microservice in the back-end, allowing us to merge into a common data model and thus reducing complexity as well as optimize the user experience.
Iteration-0 — GraphQL on Java

GraphQL on Java was an obvious choice because the technology matched the experience on our agile engineering teams. At the time this was seen as a pure backend aggregation for Rest APIs using GraphQL queries and it would not necessarily deal with mutations or subscriptions. The schema was thought about from a top-level user domain and was broken down into User Type/Role-based schema. However, as we continued to iterate, the need for sharing domain objects between schema was evident as well as support for mutations.
Iteration-1 — Multiple GraphQL Services

While GraphQL on Java worked great for queries, we lacked support for mutations. In our pursuit to scale up and accelerate development across agile teams and skillsets, we ended up adding GraphQL on NodeJS as an option that supported both queries + mutations. This was mainly done for a couple of primary reasons:
- Front-End microservice developers continued to have problems wrapping query patterns use-cases behind REST APIs
- GraphQL on Java couldn't have served the needs without service-specific logic implemented at the GraphQL gateway thus introducing tight coupling.
While we met deliverables, this left us with a decentralized schema model. As we continued to iterate there was also a need to support subscriptions.
Iteration-2 — Enter AWS AppSync

Introduction of AWS AppSync was timely for Houghton Mifflin Harcourt as we continued to iterate and scale up on GraphQL as well as evaluating Schema Stitching (now deprecated in favor of Apollo federation), Apollo GraphQL Server Federation and more. AWS AppSync at its core uses a single data graph Schema, powered by AppSync Resolvers that can aggregate and manipulate data across one or more microservices using AppSync Data Sources.
AWS AppSync offers a variety of Data Sources for Resolvers such as DynamoDB, Amazon Aurora (Serverless), Elastic Search, HTTP, and AWS Lambda. Something to consider while we planned out Appsync Data Sources is that AWS AppSync is a managed service and does not necessarily see resources within the VPC at the moment. For instance, when using HTTP resolvers, AppSync will not be able to see private APIs (deployed within your VPC), however, they work great for public APIs. At Houghton Mifflin Harcourt, we chose AWS Lambda resolvers over HTTP since it allowed us the flexibility to integrate with both private/public microservices over the VPC. One other benefit of using AWS Lambda for your data source is that it opens up the possibility for integration against other AWS services that may not be supported by AWS AppSync out of the box such as Amazon Elastic Cache, Amazon RDS, Amazon Neptune, etc.
Iteration-2.1 — Secure AWS AppSync with Amplify
AWS AppSync allows a bunch of options to secure your APIs, namely
- API Keys (API_KEY)
- Amazon Cognito User Pools (AMAZON_COGNITO_USER_POOLS)
- OpenID Connect (OPENID_CONNECT)
- AWS Identity and Access Management (AWS_IAM)
API Keys are a great start for development environments and quickstarts. For your managed environments it would usually be one among the other 3 options. At Houghton Mifflin Harcourt we chose to secure our APIs with Cognito User Pools backed by an Open ID Connect Provider (Federated). AWS AppSync supports auth directives and descriptive rules in your schema such as:
@aws_cognito_user_pools
@aws_authWith directives, it is easy to configure security rules for your schema. One could also use conditionals in your resolver templates for authorization. Resolvers are powered off Velocity Templates and are easy to code, configure, and allow you to deal with request and response objects.
#if($context.result["Owner"] == $context.identity.username)
$utils.toJson($context.result)
#else
$utils.unauthorized()
#endThis could prove pretty useful to offload authorization from your microservices and/or add an additional layer of security for your private APIs. Another useful feature with AWS AppSync is the Pipeline Resolver. This feature allows you to execute multiple operations (functions) before/after request/response execution to your data source to resolve a single GraphQL field and then execute them in sequence. Pipeline resolver could prove very handy for some use-cases intended to customize request/response for a data source, or to add additional security, etc.
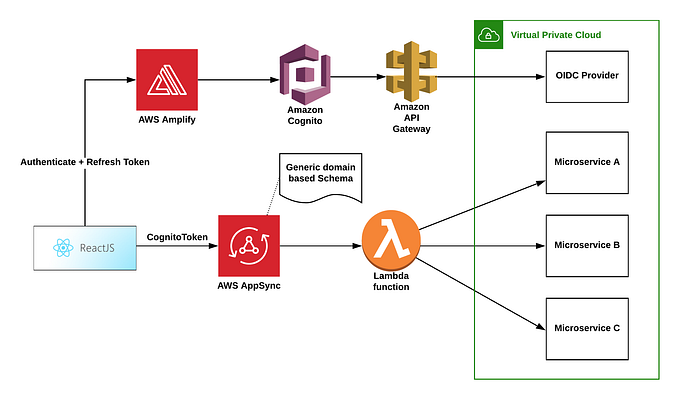
The AWS Amplify framework offers rich support for developer tools, building, and deploying AWS services. With AWS Amplify JS and only a few lines of code, one could build integration with Amazon Cognito based authentication handling generating a Cognito token as well as token refresh upon expiry.
The AWS blog GraphQL-Security-AppSync-Amplify and the Amplify JS examples do a great job describing the security options in more detail, configuration examples along with best practices and use-cases. Another great resource I suggest would be Awesome AWS AppSync, a curated list of blogs, videos, reactJS reference applications that help you get started and more.
Iteration-2.2 — Subscriptions and Local Resolvers
Subscriptions are a great way to deliver optimal user experience with Real-Time data. Subscriptions are triggered by mutations and the mutation selection set is sent to the subscribers. The AppSync SDK uses either pure WebSockets or MQTT over WebSockets as the protocol between the client and service. In practice, it is quite possible that we have a mixed bag of applications and that all the data that you may want to subscribe to may not necessarily be mutated from the get-go and may be phased out as part of your migration plans to GraphQL. It is also possible that we may want to subscribe to real-time data that may be updated by back-end systems and services.

At Houghton Mifflin Harcourt, we run an Apache Kafka based event service that microservices integrate with for entity updates (pub/sub) that our GraphQL clients need to be subscribing to. A NOOP mutation (one that is not attached to a resolver) described with the GraphQL schema allows us to notify subscribers for events originating from the microservices (back-channel) and not necessarily tied to mutations or user-driven action on the GraphQL client application.
Iteration-2.3— Dev, CI, Test and Deploy
Managing a single, cohesive schema does pose a challenge. However, using a micro frontend pattern ideally over monorepos does ease the collaboration, sharing, and contributions across application developers and agile teams.
For deployments, if you were using Serverless deploys, AWS Amplify, or AWS Code Deploy as I mentioned earlier in the post, a lot of concerns with development, testing, and deployments are taken care of out of the box. For instance, AWS Amplify has very good IDE integration for developers and also allows you to mock and test GraphQL APIs locally.
At Houghton Mifflin Harcourt, we manage AWS infrastructure with Terraform and GIT Workflow and posed an interesting challenge for developers to code/build/test and release AppSync updates with confidence.
We will be describing the development and CI process in more detail and our approach resolving some of the challenges mentioned earlier in a subsequent blog post in this series.
What’s Next?
Performance improvements and considerations
- Rest APIs are great for many use-cases but it may not always be a straight fit for integration with your GraphQL resolver. For instance, a Graph query may choose to limit results on the page, and its best if your microservices can honor them as well.
- AWS AppSync integrates with AWS Elastic Cache and is a great option to offload traffic for data that is cacheable and/or frequently requested.
- It’s still early days with AWS AppSync at Houghton Mifflin Harcourt and we are learning as we continue to look at the performance characteristics with AWS AppSync and AWS Lambda based resolvers. Something that we will be testing and looking forward to would be Provisioned Concurrency for AWS Lambda.
- Continue to review the Single Schema evolution against AWS AppSync limits. A lot of these limits are in fact a good thing and enforce best practices for both GraphQL and microservice development.
- Review the single schema approach and the developer experience for agile teams, optimize with options such as GraphQL Modules, components, etc with wider adoption of monorepos and micro frontend architecture.
Conclusion
I’d like to thank you for giving this a read and I hope our story on the GraphQL journey, our bumpy road with GraphQL adoption, and our experience integrating with AWS AppSync does help with yours!
While we have had several iterations with GraphQL we believe it is still a new beginning with AWS AppSync and other exciting cloud and serverless technologies ahead of us! We will continue to share our learnings through this series of blog posts!
Thank you!
- to the AWS team — Brice Pelle, Chanda Fortuna for their support on AWS AppSync along this journey!
- to the Houghton Mifflin Harcourt Engineering team working through all the challenges!
- to Matt Hanlon Darragh Grace Anne-Marie McCullagh for their feedback on this post!

